Your First AI Loop Should Be for Yourself (Template Included)
Mine Claude Code and Codex sessions for content ideas, tool fixes, skills, hooks, and safer self-improvement loops. Template included.
Jun 22, 2026
11 min read
I spend a ridiculous amount of my day in Claude Code, Codex, and a terminal.
Not just coding. Researching. Drafting. Pulling reports… Or just playing around with a random GitHub repo I found while scrolling.
Which means my terminal has accidentally become a pretty honest record of how I work.
The funny part is that I often do not notice what I am doing until someone is over my shoulder watching me. They will stop me halfway through some ordinary little workflow and ask, “Wait, how did you know to do that?” or “Why did you run that command first?” To me it was invisible. To them it was interesting and they wanted to do it.
That is the loop I care about and is the point of this whole article.
Not an agent loop where the point is “make the agent more autonomous.” A self-improvement loop where the point is: mine the work you are already doing, then use it to make yourself, your setup, and your content better.
For the last few weeks I have been reading my own Claude and Codex sessions every day, not as conversations, but as evidence. What am I doing repeatedly? What do I explain to agents over and over? What did I do in the terminal that would make a useful article, prompt, diagram, product, or tutorial if I noticed it in time?
Some of my most useful and popular tweets came from in the moment sharing something I discovered while working. The AI space moves fast and lessons evaporate as we move on to the next thing.
So that’s why I created the improvement loop, for myself (and for my agents), but I started with myself.
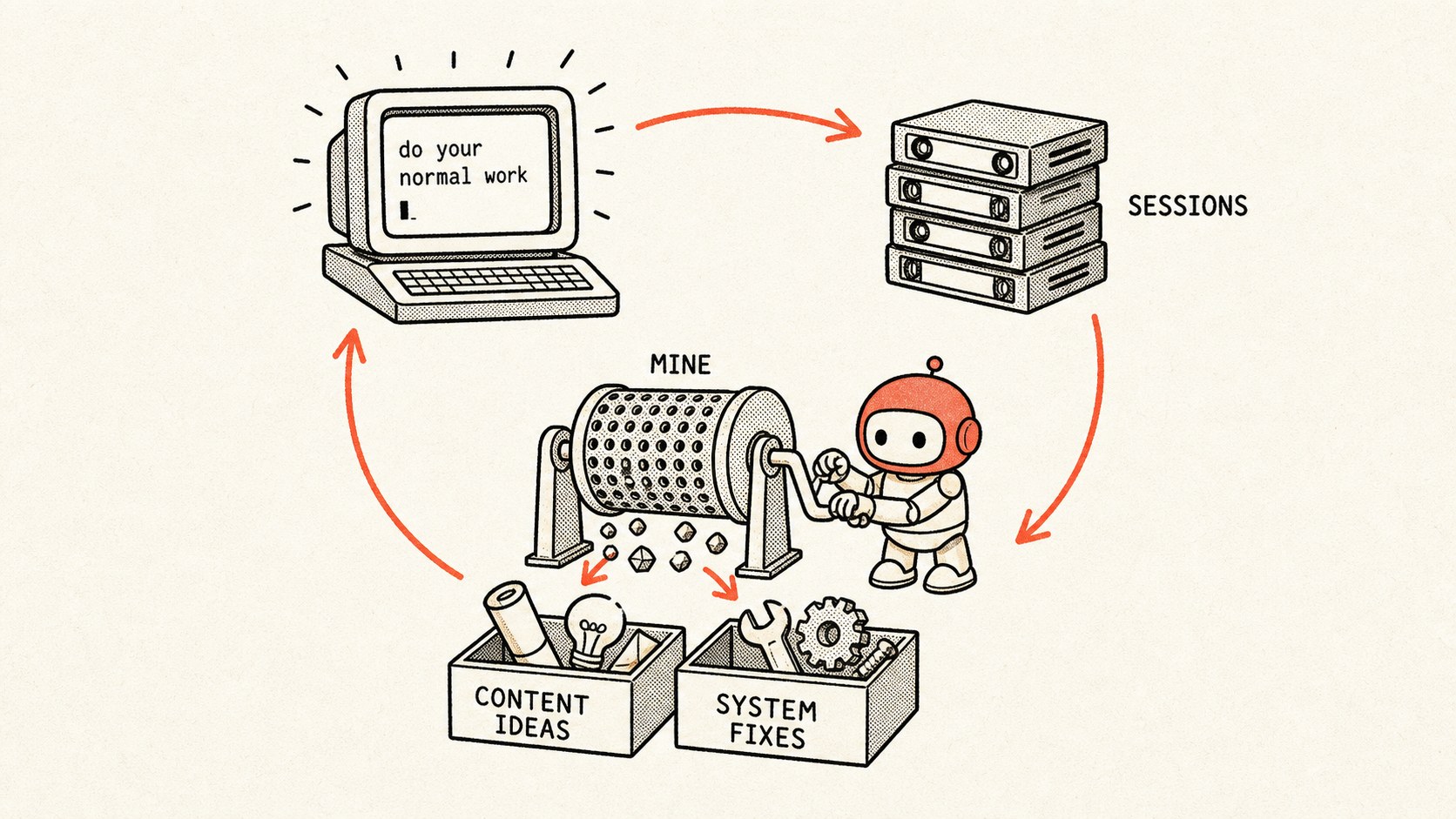
The first loop worth building is the one that reads your own recent sessions and asks two questions:
- What should I create from this?
- What should I fix so tomorrow is easier?
Why this loop first
Most people aim AI at output because output is the visible win. A post got drafted. A bug got fixed. A spreadsheet got cleaned up. An app got built. Lovely.
But the bigger opportunity is the pattern underneath the output.
If I use the terminal all day, it is full of accidental curriculum. It shows what I am actually learning, what I am repeatedly fixing, what shortcuts I use without thinking, where my tools still annoy me, and what I should probably teach other people. Where my custom-built CLI could be better.
That compounds in two directions.
First, it improves the work. Every fix you make to a context file, command, skill, hook, tool, or config pays off in every future session that touches it. Both in time, efficiency and accuracy.
Second, it gives you ideas for content. Every repeated behavior is a possible article, tweet, workshop section, lead magnet, or example.
Not because you sat down to “brainstorm content” 🙄, but because your actual work left tracks.
The two-loop version
The simple way to think about it is inner loop, outer loop.
The inner loop is the work you are already doing in Claude Code, Codex, or the newest girl at the dance, GLM 5.2. Sometimes that is agentic coding. Sometimes it is research. Sometimes it is “why is this export broken and why is it somehow my problem?”
The outer loop is the one watching those runs after the fact. It does not try to do the work again. It asks what the work revealed about you and your setup.
-
Did I do something clever that another person would ask about if they were watching? That is a content idea.
-
Did the agent use the wrong command because the help text is bad? That is a tool fix.
-
Did I correct it about the same repo convention for the third time? That is a context-file fix.
-
Did I type the same five-step workflow again? That is probably a slash command.
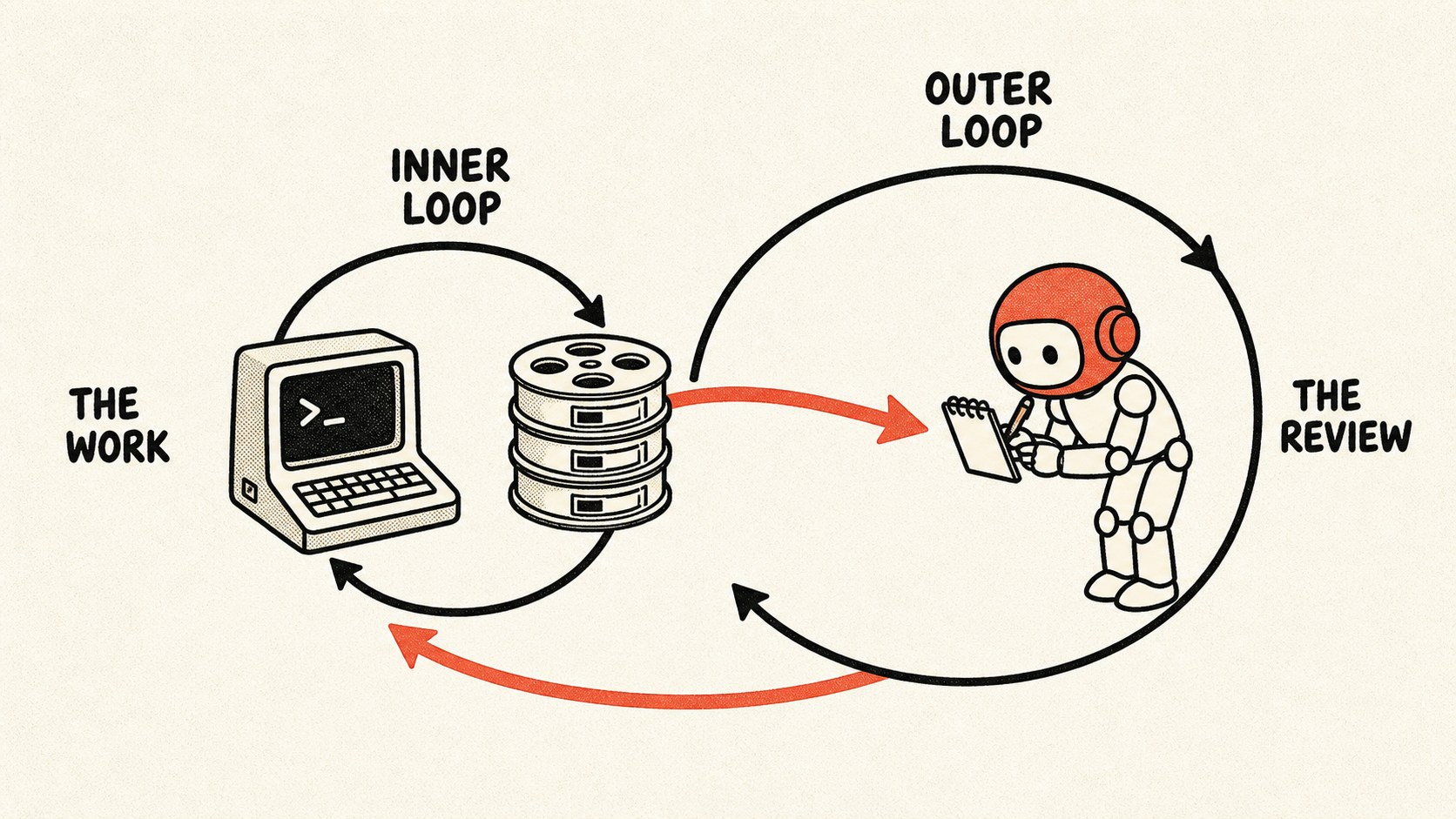
This distinction matters because “self-improving agent” sounds like the agent is allowed to wander around rewriting itself. That is not what I want. I want a scout that brings back evidence and says, “This part of the day had signal.”
Then I decide what changes.

The two questions, and where the answers go
Underneath everything are two questions I run against every recent session:
What did I do here that is worth turning into content?
What reusable improvement would have made this session shorter, safer, cheaper, more correct, or less annoying?
The first question catches the things I am too close to notice. The little workflows. The weird judgment calls. The “oh, I just always do it that way” moves that are invisible until someone else asks.
The second question catches the system debt.
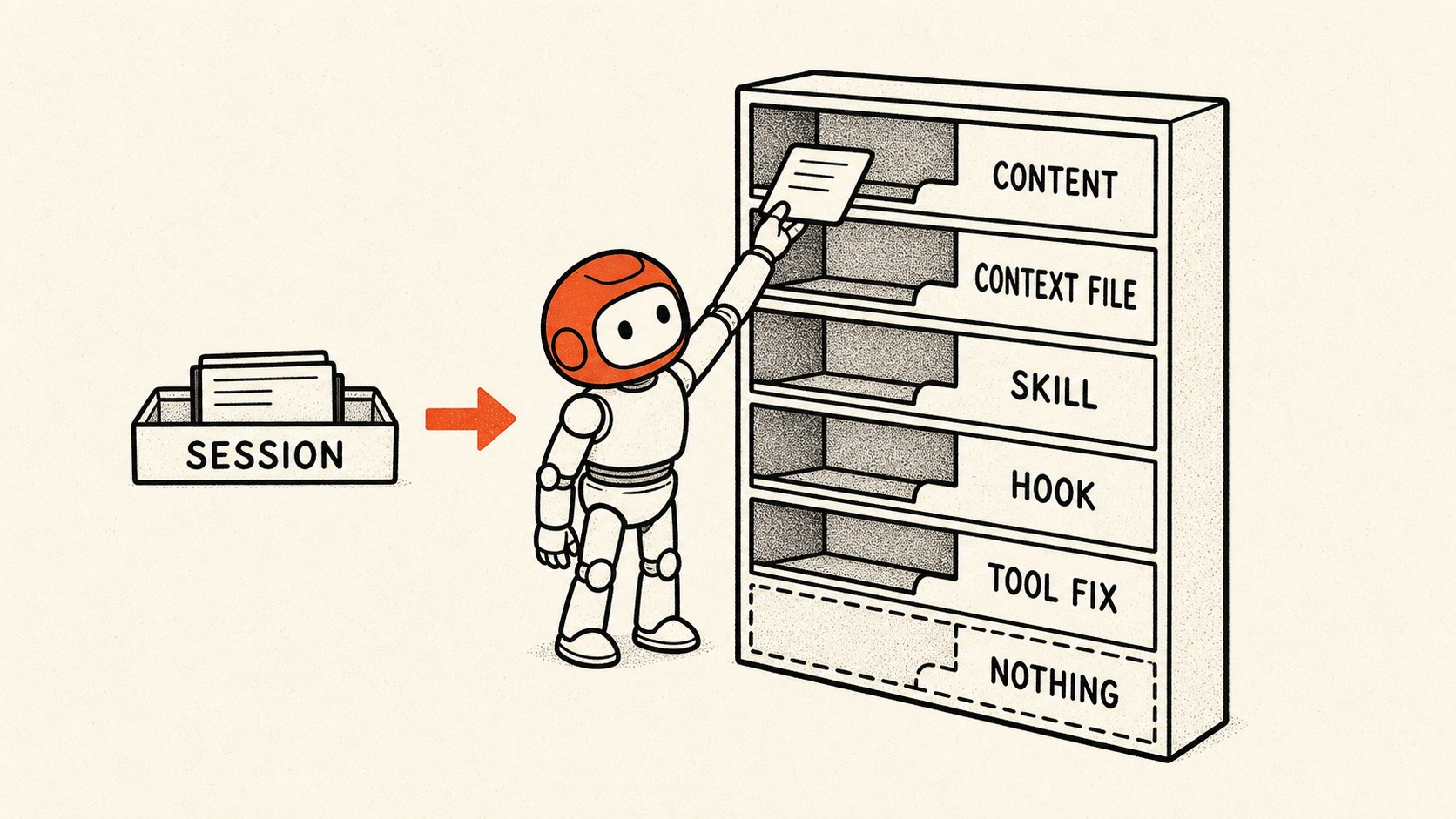
Noticing is the easy part. The hard part is deciding what kind of lesson you found and where it belongs. When I read a session back, I am looking for one of seven homes for the lesson:
Content idea
- Did I do something another person would ask me to explain?
- Did a throwaway terminal session reveal a framework, shortcut, product idea, lesson, or story?
- This is the bucket I used to ignore, which is hilarious because it is often the most useful one.
Context file
• Could anything in this session have lived in CLAUDE.md or AGENTS.md so you never explain it again? • A path you kept pasting. • A convention the agent guessed wrong. • If you said it out loud to the agent twice, it probably wanted to be written down once.
Slash command
• Which command should have been running and wasn’t?
If you found yourself typing the same five-step instruction from scratch, that is a command you do not have yet.
Skill
• Which skill needs updating, and which skill should exist that doesn’t, because you keep doing the same thing by hand? • Patch the skill you already have instead of minting a new one for every incident. • A good skill prevents a whole class of mistakes or a whole new type of efficiency / quality
Hook
• What should happen automatically, every time, instead of depending on you remembering? • A check before a commit. • A redaction pass before anything gets shared. • A reminder before you publish.
Hooks are the part people forget they can change, and often the highest-leverage fix, because a hook never has a bad Tuesday.
Tool or CLI
Did you reach for a tool and it stumbled? This is the bucket people skip, and the one that matters most. Was the command awkward? Was the output hard to parse? Was the error unclear? Was it missing a JSON flag, returning silent nulls, or forcing three commands where one would do? If so, the fix is not a better prompt. A model can remember an instruction. A tool can remove the need for the instruction. One of those is permanent.
I wrote a whole article about why you should be using agentic CLIs.
Config
Sometimes it is not a skill or a tool. It is a setting. A permission you keep approving by hand, an environment variable, a default that is wrong for how you work. Change the config once and the friction is gone for good.
What it looks like when it runs
I open-sourced my version here. It looks for real tool calls, shell commands, failures, skill use, and the moments I corrected the agent.
On its first real run, it found signals in 37 sessions and staged 7 proposals: one CLI fix, four skill reviews, one memory or runbook update, and one backlog item.
The proposals were not abstract either. They were annoyingly specific, which is exactly why they were useful. One example:
The CLI command was technically correct and still impossible to guess
My Wavespeed image-generation CLI, wavespeed-pp-cli that I used for all the nontechnical.dev illustrations were failing because the agent guessed the wrong syntax for saving a reusable image profile. First: “accepts at most 1 arg, received 3.” Then: “unknown flag: —model-id.” The lesson was not “tell agents to read help more carefully.” The lesson was: if the correct command shape is that easy to guess wrong, the CLI needs a better alias and better examples.
I write up loops like this one every week. The newsletter is where I share what actually changed in my setup, the autonomy rules, and the things I would not let an agent do unsupervised. Join the Little Might newsletter →
No Self-Surgery
I want the system to notice patterns. I do not want it quietly rewriting my instructions, publishing my content ideas, or deciding that one weird freaky Friday is now a new rule.
So the rules are boring on purpose:
- Store evidence, not transcript dumps.
- Detect real tool use, not mentions.
- Separate durable lessons from one-off.
- Patch existing skills before creating new ones.
- Require approval before anything changes.
Everyone wants autonomy because autonomy sounds impressive. In real life, the valuable thing is controlled compounding. I’m sure in weeks/months I will not need to review much but for now I want to know what’s changing before it does.
Then there’s the real outer loop, which is reviewing what changed based on the review. And now we’re getting into inception territory.
Set it up today
You do not need a custom command to get the benefit. You need the manual version, and you can run it in the next ten minutes with the agent you already have.
Your sessions are already on your disk. Claude Code stores them as JSONL files under ~/.claude/projects/, one folder per project. Codex stores them under ~/.codex/sessions/, sorted by date. That is the raw material. You do not have to read them like a diary. You read them like ops data.
Open Claude Code or Codex in that folder and hand it this:
Read my 20 most recent sessions.
Claude Code sessions live in ~/.claude/projects/*/*.jsonl
Codex sessions live in ~/.codex/sessions/<year>/<month>/<day>/rollout-*.jsonl
Each file is JSONL: one event per line, including my messages, your tool
calls, shell commands, and their output.
Find the useful patterns:
- things I did that would make a good article, tweet, tutorial, diagram, prompt, product idea, or example
- commands or tools that errored, or that I ran several times before they worked
- moments I corrected you ("no", "actually", "that is wrong", "do not do that again")
- the same setup step rediscovered in more than one session
For each pattern, tell me where it belongs:
- a content idea to draft or add to my idea library
- a line to add to CLAUDE.md or AGENTS.md
- a slash command or skill to add or update
- a hook that should run automatically
- a tool or CLI that should be fixed
- a config or settings change
- or nothing, if it was a one-off
Redact anything sensitive (emails, tokens, keys) in what you show me.
Do not change anything yet. Give me a numbered list of proposals, each with
the one evidence line it came from. I will tell you which ones to apply.This is still my most useful personal loop. Read the proposals, pick one, tell the agent to apply it, and watch it actually change something in your setup.
If you would rather start from something already built, the version I run is open source: agent-improvement-loop. It does exactly this, on a schedule, with the same rule baked in: it scans and stages, you approve.
Make it run every day
A loop you have to remember to run is not a loop. The fix is to split it in two: let the boring half run on a timer, and keep the judgment half for yourself.
The scan is safe to automate, because it only reads sessions and stages proposals. It changes nothing. So put it on a schedule and forget about it.
First, turn that prompt into a command you can run by name. In Claude Code, save it as a file at ~/.claude/commands/mine-sessions.md, with the prompt as the body. Now /mine-sessions runs it any time.
Then schedule it. The simplest version is one line in cron, or a launchd job on a Mac, that runs the command headless every morning:
# 7am daily: mine yesterday's sessions and stage proposals for review
0 7 * * * cd ~/your-project && claude -p "/mine-sessions" >> ~/agent-review.log 2>&1If you live in Claude Code, you can skip cron and schedule the /mine-sessions command to run daily as a routine instead. Either way, the proposals are waiting for you in the morning.
One rule, and it is the important one: schedule the scan, never the changes. The morning job reads and stages. You still open the list with your coffee, approve the two fixes worth doing, and throw the rest away. The day a weird Tuesday tries to rewrite your setup, you want to be the one holding the pen.
If you are in Claude Code or a terminal every day, your sessions already contain the raw material: the work you do, the mistakes you repeat, the shortcuts you forgot were shortcuts, and the ideas hiding in plain sight.
The goal is not an agent that runs forever. The goal is a system that makes you slightly better at your own work tomorrow because of what happened today.
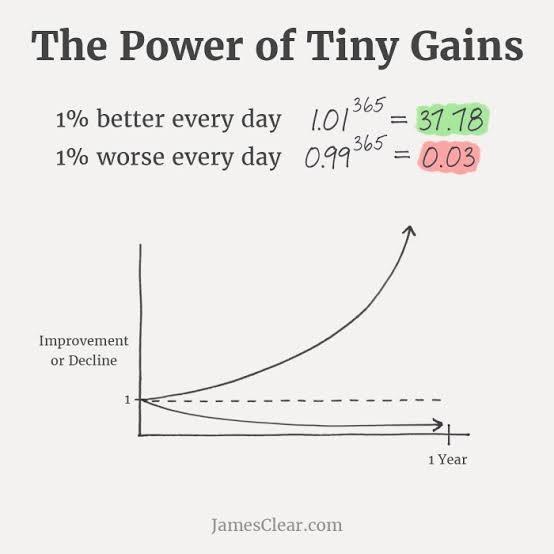
The Power of Tiny Gains is the whole point. Tiny gains compound. Tiny frictions compound too.
Template included: agent-improvement-loop on GitHub
More from Little Might
If you want the adjacent rabbit holes, these are the ones I would read next:
- Why we need to build a second internet for our agents
- How to build an AI house manager for your family
- How to stop your AI images from drifting across a series
And if you want the weekly version of this, I write the Little Might newsletter here: littlemight.com

Written by
Cathryn Lavery
Cathryn went from designing buildings to architecting products. She founded BestSelf, bought it back from private equity in 2024, and rebuilt it AI-native. She's currently building something new in AI. Little Might is where she doesn't have to keep it all in her head.
Related reading
-
Jun 10, 2026
How to set up multiple Macs for always-on AI agents
-
Feb 16, 2026
Why Your OpenClaw Agent Doesn't Remember You
-
Jun 11, 2026
How to stop your AI images from drifting across a series
-
Jun 1, 2026
How to Access Your OpenClaw or Hermes Agent From Anywhere
-
May 27, 2026
How I Plan Projects With AI: The Beads Workflow